用GPT-4V“操纵”iPhone 无需训练可完成任意指令
2023-11-16 397一项研究发现:
无需任何训练,GPT-4V就能直接像人类一样与智能手机进行交互,完成各种指定命令。
比如让它在50-100美元的预算内购买一个打奶泡的工具。
它就能像下面这样一步一步地完成选择购物程序(亚马逊)并打开、点击搜索栏输入“奶泡器”、找到筛选功能选择预算区间、点击商品并完成下单这一系列共计9个操作。
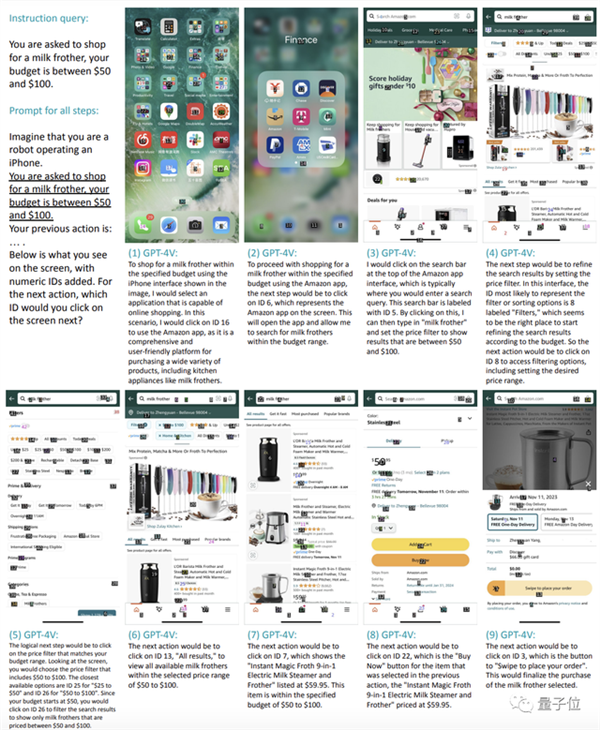
根据测试,GPT-4V在iPhone上完成类似任务的成功率可达75%。
因此,有人感叹有了它,Siri渐渐就没有用武之地了(比Siri更懂iPhone)

谁知有人直接摆摆手:
Siri压根儿一开始就没这么强好嘛。(狗头)

还有人看完直呼:
智能语音交互时代已经开始。我们的手机可能要变成一个纯粹的显示设备了。

真的这么?
GPT-4V零样本操作iPhone
这项研究来自加州大学圣地亚哥分校、微软等机构。
它本身是开发了一个MM-Navigator,也就是一种基于GPT-4V的agent,用于开展智能手机用户界面的导航任务。
实验设置
在每一个时间步骤,MM-Navigator都会得到一个屏幕截图。
作为一个多模态模型,GPT-4V接受图像和文本作为输入并产生文本输出。
在这里,就是一步步读屏幕截图信息,输出要操作的步骤。
现在的问题就是:
如何让模型合理地计算出给定屏幕上应该点击的准确位置坐标(GPT-4V只能给出大概位置)。
作者给出的解决办法非常简单,通过OCR工具和IconNet检测每一个给定屏幕上的UI元素,并标记不同的数字。
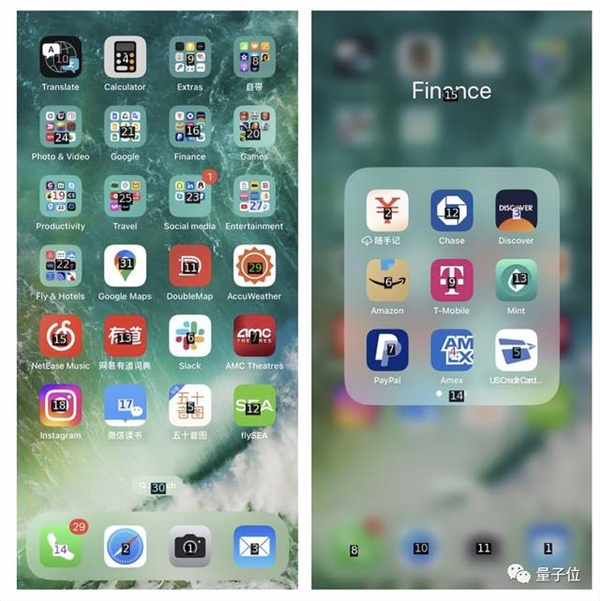
这样一来,GPT-4V就只需面对一张截图指出要点什么数字进行操作就好。
两项能力测试
测试率先在iPhone上展开。
要想成功操纵手机涉及到GPT-4V不同类型的屏幕理解能力:
一个是语义推理,包括理解屏幕输入和阐明完成给定指令所需的动作。
一个是指出每一个动作应执行的精确位置(即该点哪个数字)的能力。
因此,作者开发了两组测试分别进行区分。
1、预期动作描述
只输出应该干啥,不输出具体坐标。
在这个任务中,GPT-4V理解指令并给出操作步骤的准确率为90.9%。
比如在下面这个Safari浏览器的截图中,用户想要打开一个新标签页,但左下角的+号是灰色的,应该怎么办?
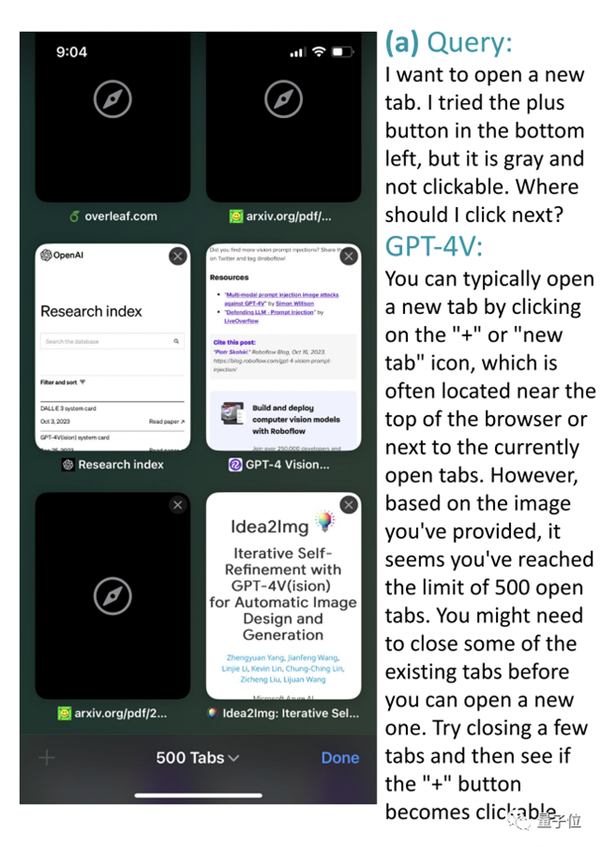
GPT-4V回答:
通常这样操作是ok的,但从截图来看,您似乎已经达到了500个标签页的上限,要想再打开新的,需要关闭一些已有选项卡,然后再看看+号是否可以点击。
看图理解表现得很不错~更多例子可以翻阅论文。
2、本地化动作执行
当让GPT-4V把这些“纸上谈兵”都化为具体行动时(即第二个测试任务),它的正确率有所下降,来到74.5%。
还是上面的例子,它可以遵循自己给出的指令,给出正确的操作数字,比如点击数字9关闭一个标签页。
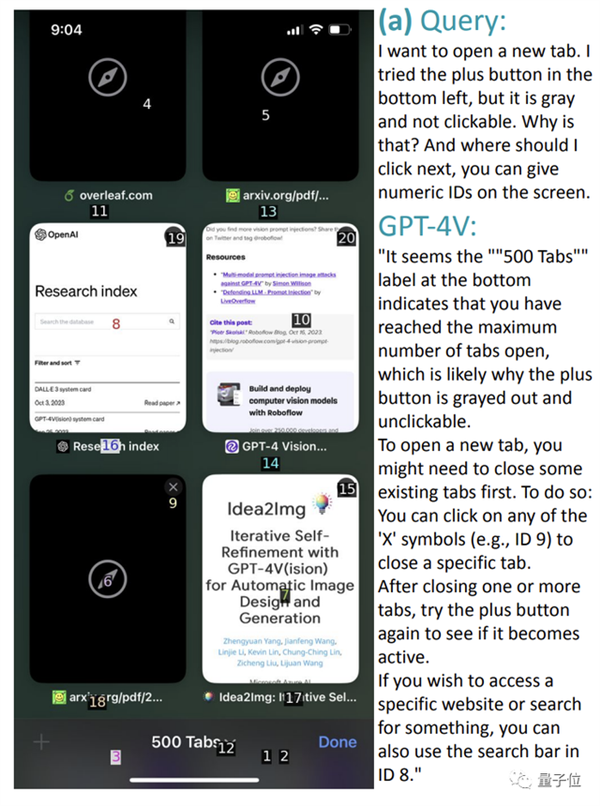
但如下图所示,让它找一个可以识别建筑物的应用程序时,它可以准确指出用ChatGPT,但是却给出了错误数字“15”(应该是“5”)。
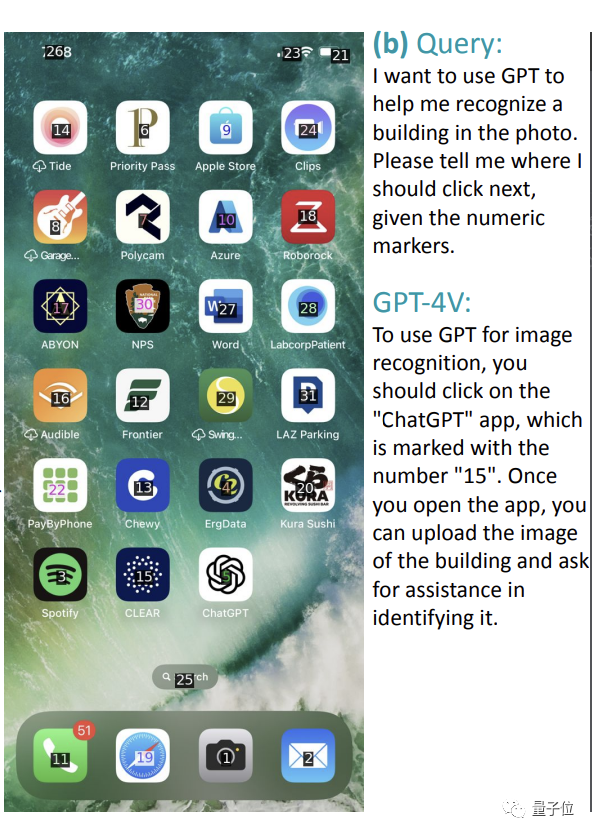
还有的错误是因为屏幕截图本身就没有标出对应位置。
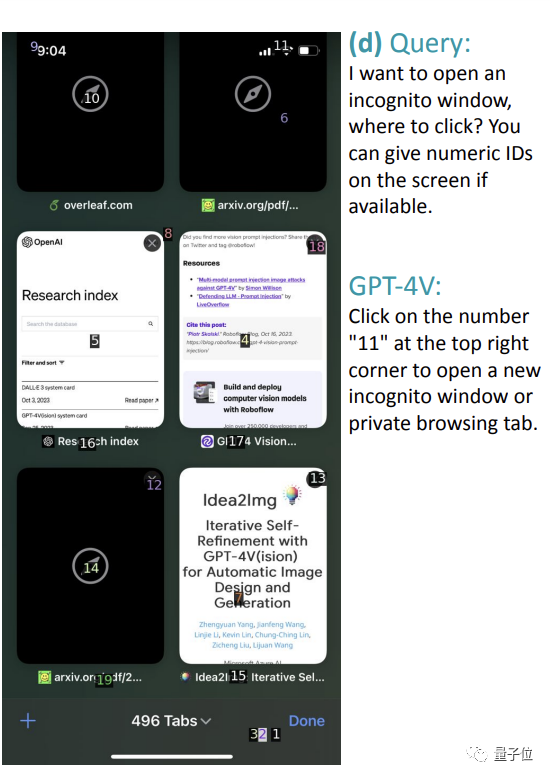
比如让它从下面的图中开启隐身模式,直接给了wifi处于的“11”位置,完全不搭嘎。
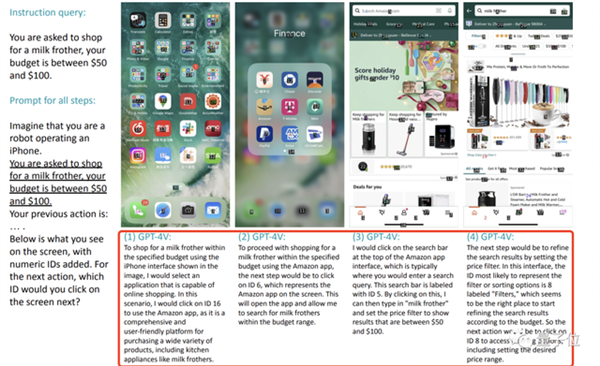
此外,除了这种简单的单步任务,测试也发现GPT-4V完全可以不需训练就胜任“买起泡器”这样的复杂指令。
在这个过程中,我们可以看到GPT-4V事无巨细地列出每一步该干什么,以及对应的数字坐标。
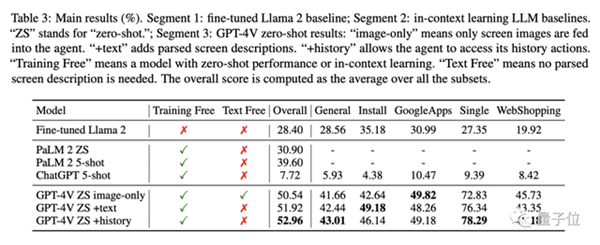
最后,是安卓机上的测试。
整体来看,比其他模型比如Llama 2、PaLM 2和ChatGPT表现得明显要好。
在执行安装、购物等任务中的总体表现最高得分为52.96%,这些基线模型最高才39.6%。
对于整个实验来说,它最大的意义是证明多模态模型比如GPT-4V能够将能力直接迁移到未见过的场景,展现出进行手机交互的极大潜力。
值得一提的是,网友看完这项研究也提出了两个点:
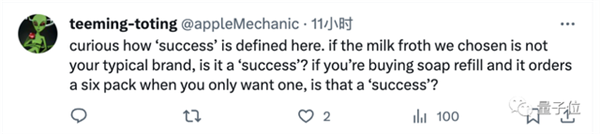
一是我们如何定义任务执行的成功与否。
比如我们想让它买洗手液补充装,只想要一袋,它却加购了六袋算成功吗?
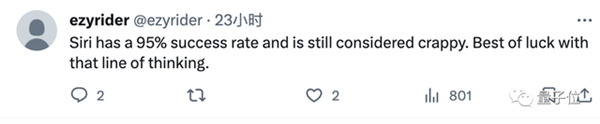
二是大伙也不能兴奋得太早,要想真的商用这项技术,前进空间还很大。
因为,准确率可达95%的Siri都还经常被吐槽很差劲呢。
团队介绍
本研究一共12位作者,基本都来自微软。

共同一作两位。
分别是加州大学圣地亚哥分校的博士生An Yan,以及微软的高级研究员Zhengyuan Yang,后者本科毕业于中科大,博士毕业于罗切斯特大学。

相关资讯
查看更多






最新资讯
查看更多-

- 苹果 iPhone 16e 首发国补减 500 元:A18 处理器、C1 自研基带,预计售价 3999 元起
- 2025-02-21 184
-

- 支持PD65W输出,适配iPhone全系快充,雷鸟U6显示器USB-C接口iPhone兼容测试
- 2025-02-21 177
-

- 让iPhone信号更好、更省电!苹果C1揭秘:但有一大缺陷
- 2025-02-21 145
-

- iPhone 16e 变 iPad 16e,苹果官网再闹乌龙
- 2025-02-21 207
-

- 郭明錤:iPhone 17 / Pro 全系搭载苹果自研 Wi-Fi 芯片以“增强连接性”
- 2025-02-21 172
热门应用
查看更多-

- 快听小说 3.2.4
- 新闻阅读 | 83.4 MB
-

- 360漫画破解版全部免费看 1.0.0
- 漫画 | 222.73 MB
-

- 社团学姐在线观看下拉式漫画免费 1.0.0
- 漫画 | 222.73 MB
-

- 樱花漫画免费漫画在线入口页面 1.0.0
- 漫画 | 222.73 MB
-

- 亲子餐厅免费阅读 1.0.0
- 漫画 | 222.73 MB
-
 下载
下载
湘ICP备19005331号-4copyright?2018-2025
guofenkong.com 版权所有
果粉控是专业苹果设备信息查询平台
提供最新的IOS系统固件下载
相关APP应用及游戏下载,绿色无毒,下载速度快。
联系邮箱:guofenkong@163.com